大量のデータを高速に処理するために並列処理を実装する場合、ホットスポットに注意する必要がある。ホットスポットというのは、同時にリクエストやトランザクションが集中してパフォーマンスの低下を引き起こす箇所を指す。この記事では特にデータベース上のレコードについて取り上げる。
ホットスポットがあると、どれだけ並列数を増やしても特定のレコードへのトランザクションが集中し、ロック待ちによるエラーが増え続けることになるため、パフォーマンスが改善しない。
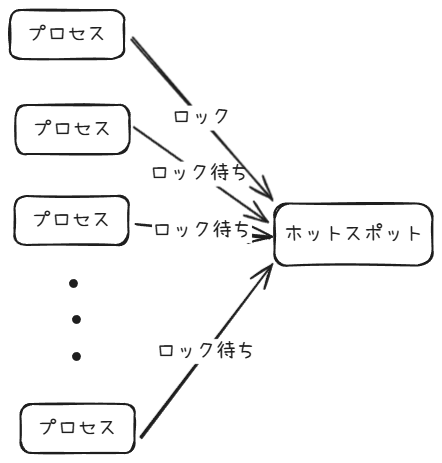
ホットスポットを回避するための方法としては
- 必要のない場面でトランザクションを使わない
- indexを適切に設定してロックを取得する範囲を制限する
- 特定のレコードにアクセスが集中しないテーブル設計
あたりが考えられると思う。この記事では特にテーブル設計について深堀りしたい。
例:グループへの追加
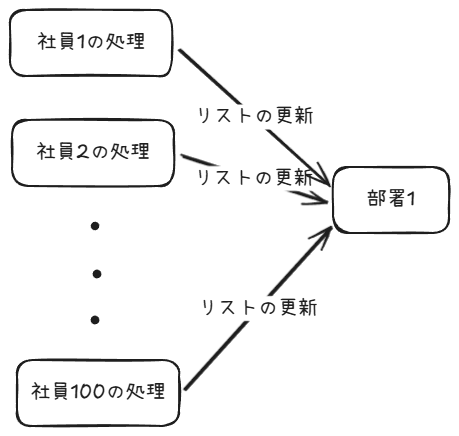
部署の統合によって社員の所属する部署をいっきに変更する処理を考えてみる。部署を変更する社員がたくさんいると、それだけ処理に時間がかかるため社員ごとの処理を並列におこなえるようにしたい。
このとき、部署テーブルに所属する社員のIDをリストとしてもっていたらどうなるか。
+----+--------+-----------+
| id | name | staff_ids |
+----+--------+-----------+
| 1 | 開発部1 | [1, 2, 5] |
+----+--------+-----------+
| 2 | 開発部2 | [3, 4] |
+----+--------+-----------+
社員ごとの処理のなかで部署レコードの社員IDリストを更新するために、同じ部署レコードへのアクセスが集中することになる。意図しない形でリストが更新されないように、ロックをとりながら更新を進めることになるため、冒頭に書いたようなロック待ちが大量に発生することになる。
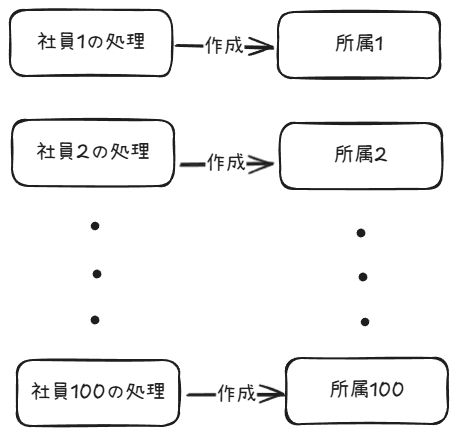
こういったグループへの追加・削除はグループのレコードを更新するのではなくて、所属していることを表すレコードを作成・削除する形でテーブル設計するといい。例えば、以下のような所属テーブルを作る。
+----+---------+----------+
| id | dept_id | staff_id |
+----+---------+----------+
| 1 | 1 | 1 |
+----+---------+----------+
| 2 | 1 | 2 |
+----+---------+----------+
| 3 | 2 | 3 |
+----+---------+----------+
ある部署への追加は所属レコードを作成するだけで済むため、特定のレコードへのアクセスが集中することがなくなり並列処理のパフォーマンスが改善される。
例:集計
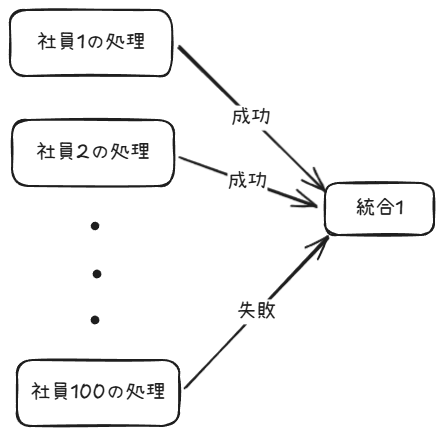
次に、並列処理によって成功した数や失敗した数を集計する場合を考えてみる。
引き続き部署の統合を例にとると、統合テーブルに移動した社員数と移動できなかった社員数を記録したいとする。
+----+---------+---------+
| id | success | failure |
+----+---------+---------+
| 1 | 99 | 1 |
+----+---------+---------+
| 2 | 100 | 0 |
+----+---------+---------+
成功した数と失敗した数を並列処理のなかで集計してしまうと、統合レコードがホットスポットになってしまう。
その代わりに、処理ごとの結果を表すためのテーブルを用意し、処理ごとの結果をステータスとして保持しておくといい。今回の例だと、社員の異動を表すための異動テーブルを用意する。
+----+---------+----------+--------+
| id | dept_id | staff_id | status |
+----+---------+----------+--------+
| 1 | 1 | 1 | 1 |
+----+---------+----------+--------+
| 2 | 1 | 2 | 1 |
+----+---------+----------+--------+
| 3 | 2 | 3 | 2 |
+----+---------+----------+--------+
そして、並列処理とは別のタイミングでこれらのステータスから成功した数と失敗した数を集計するようにする。
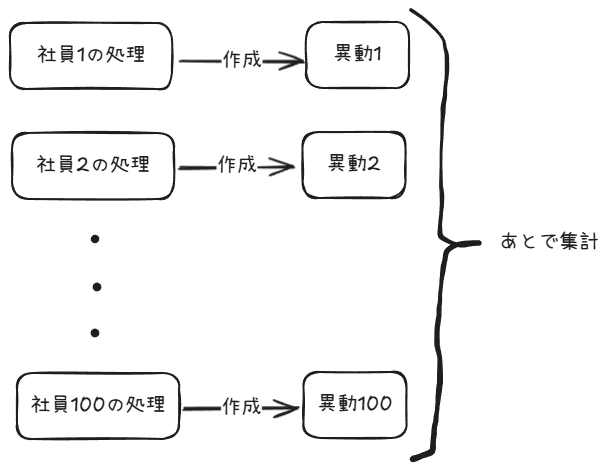
こうすることで社員ごとの処理はホットスポットをもたずに並列処理ができるため、社員が増えてもスケールするはず。
まとめ
並列処理をスケールさせるにはテーブル設計の時点でホットスポットが発生しないように工夫することが重要で、その例としてグループへの追加と集計を取り上げた。